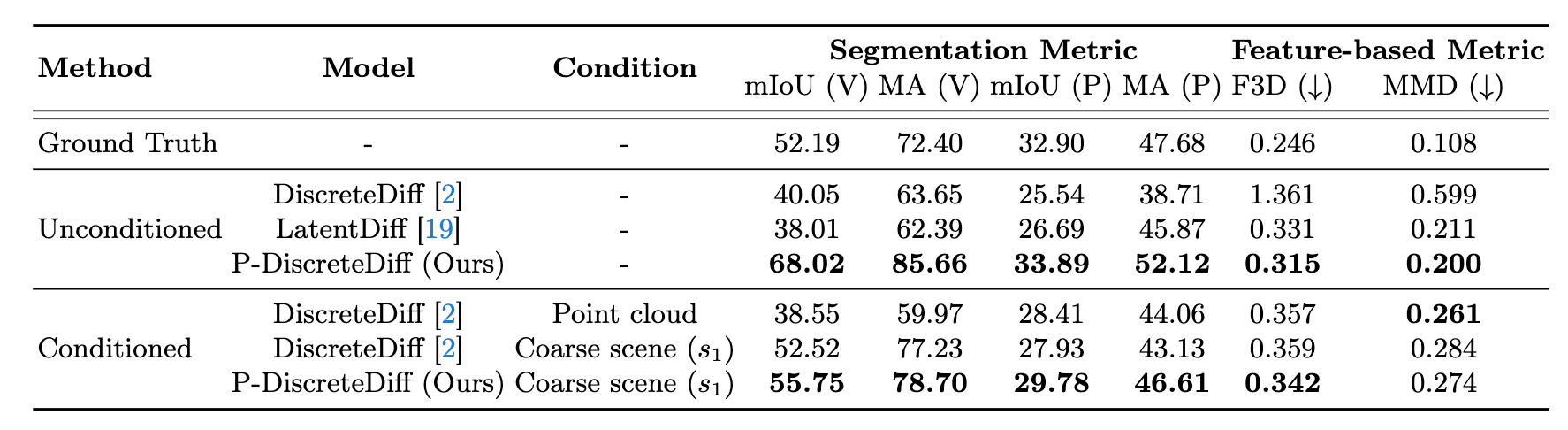
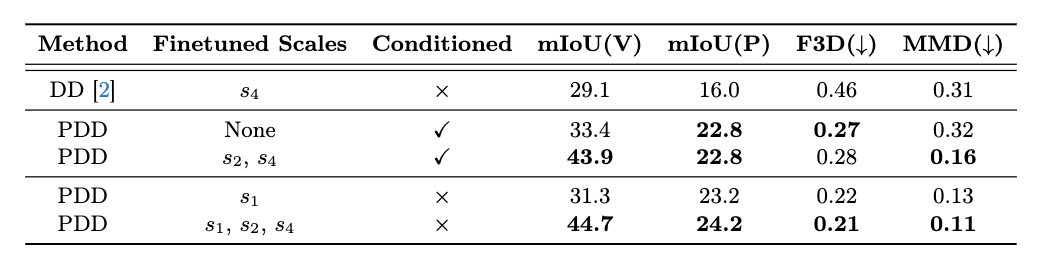
Table 1. Comparison of various diffusion models on 3D semantic scene generation of CarlaSC. DiscreteDiff, LatentDiff, and P-DiscreteDiff refer to the original discrete diffusion, latent discrete diffusion, and our approach, respectively. Conditioned models work based on the context of unlabeled point clouds or the coarse version of the ground truth scene. A higher Segmentation Metric value is better, indicating semantic consistency. A lower Feature-based Metric value is preferable, representing closer proximity to the original dataset. The brackets with V represent voxel-based network and P represent point-based network.
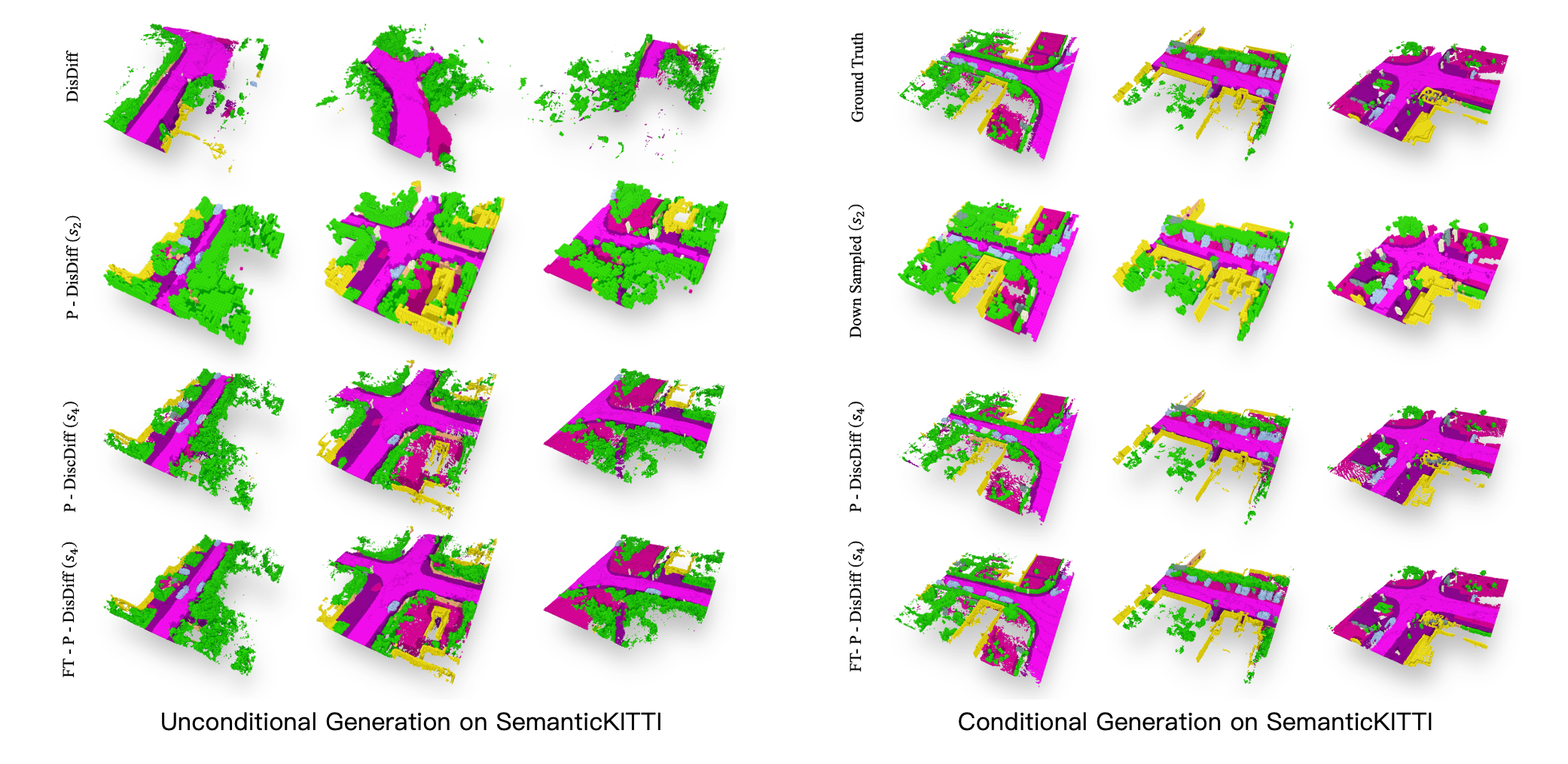
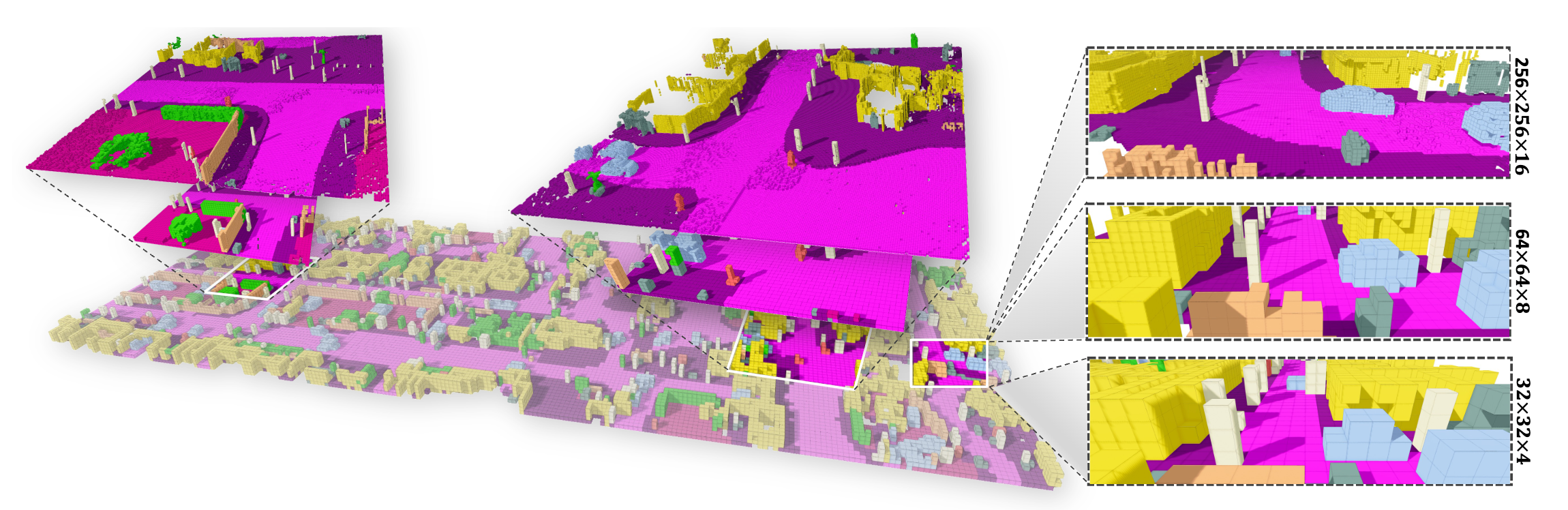
Figure 1. We compare with two baseline models – DiscreteDiff and
LatentDiff and show synthesis from our models with different scales. Our method produces more diverse scenes compared to the
baseline models. Furthermore, with more levels, our model can synthesize scenes with more intricate details.
We compare our approach with two baselines, the original Discrete Diffusion and the Latent Diffusion. The result reported in Table 1 demonstrates the notable performance of our method across all metrics in both unconditional and conditional settings in comparable computational resources with existing method. Our proposed method demonstrates a notable advantage in segmentation tasks, especially when it reaches around 70% mIoU for SparseUNet, which reflects its ability to generate scenes with accurate semantic coherence. We also provide visualizations of different model results in Figure 1, where the proposed method demonstrates better performance in detail generation and scene diversity for random 3D scene generations.
Figure 2. We conduct the comparison on conditioned
3D scene generation. We benchmark our method against the
discrete diffusion conditioned on unlabeled point clouds
and the same coarse scenes. Results in the figure
present the impressive results of our conditional generation
comparison. Despite the informative condition of the point cloud,
our method can still outperform it.
Additionally, we conduct the comparison on conditioned 3D scene generation. We benchmark our method against the discrete diffusion conditioned on unlabeled point clouds and the same coarse scenes. Results in Table 1 and Figure 2 present the impressive results of our conditional generation comparison. It is also observed that the point cloud-based model can achieve decent performance on F3D and MMD, which could be caused by 3D point conditions providing more structural information about the scene than the coarse scene. Despite the informative condition of the point cloud, our method can still outperform it across most metrics.
Figure 3. Data retrieval visualization. We generate 1k scenes using PDD on CarlaSC
dataset, and retrieve the most similar scene in training set for each scene using SSIM
(SSIM=1 means identical), and plot SSIM distribution. Scenes at various percentiles
are displayed (red box: generated scenes; grey box: scenes in training set), those with
the highest 10% similarity are very similar to the training
set, but still not completely identical.
We use distribution plots, as shown in Figure 3, to validate the
similarity between our generated scenes and the training set. We also display
three pairs at different percentiles in this figure, showing that scenes with lower
SSIM scores differ more from their nearest matches in the training set. This
visual evidence reinforces that PDD effectively captures the distribution of the
training set instead of merely memorizing it.